

Contents
You’ve probably heard about the rule to prefer standard algorithms over raw for loops. The major reason is that those algorithms say what is happening in the name and encapsulate the loop logic. But they’re not always the best choice.
Use standard algorithms
Especially the more complex algorithms can be quite messy when we implement them by hand. So, besides having the name of the algorithm in the code, it’s a good thing to have the algorithm part separated from the rest of the logic. It makes the code less complicated and thus adheres to the KISS principle. There’s a famous talk from Sean Parent about the topic, I suggest you watch it.
There’s also a famous quote:
"This is obviously a rotate" : – )
— Kate Gregory (@gregcons) May 5, 2018
As far as I know, it is supposed to come from that talk, but I haven’t found the version “obviously a rotate” yet. Actually, the whole point of preferring standard algorithms is that a manual implementation is anything but obviously a rotate – except maybe to Sean.
So, I strongly suggest you learn about those algorithms. Or, if you already know them all, keep that knowledge fresh and use it. A very good resource on that is this talk by Jonathan Boccara.
Examples…?
Let’s show some examples of for loops that can be made into algorithms. I’ve encountered examples very similar to these in the last weeks in the code base I’m currently working on. I’ll concentrate on two cases.
Copy
Imagine we get some container, handwritten or from a third party library. It has standard compatible iterators and contains a bunch of Employee data. To reuse that data in our business logic without having to use the custom container, the data is transferred into a std::vector:
OtherContainer<Employee> source;
//...
std::vector<Employee> employees;
employees.reserve(source.size());
for (auto const& employee : source) {
employees.push_back(employee);
}
Now, replacing the loop with an algorithm is straight-forward. What we do here is simply a copy:
std::vector<Employee> employees;
employees.reserve(source.size());
std::copy(std::begin(source), std::end(source), std::back_inserter(emplyoees));
Here, std::back_inserter creates a std::back_insert_iterator which does the push_back calls for us.
Looks simpler, doesn’t it? Thinking of it, there’s an even simpler version:
std::vector<Employee> employees(std::begin(source), std::end(source));
This is the iterator range constructor of std::vector, which is also present in other standard containers. So, sometimes there are even better alternatives to raw loops than standard algorithms!
Transform
Later in our code base, we want to analyze the salaries of the employees. The Employee class has a uniqueName method, so we can put all the employees’ names and salaries into a std::map:
std::map<std::string, unsigned> salariesByName;
for (auto const& employee : employees) {
salariesByName[employee.uniqueName()] = employee.salary();
}
Instead of the access operator we could have used map‘s insert method as well:
std::map<std::string, unsigned> salariesByName;
for (auto const& employee : employees) {
salariesByName.insert(
std::make_pair(
employee.uniqueName(),
employee.salary()
)
);
}
The algorithm for taking elements from one container and creating different elements for another container from them is std::transform:
std::map<std::string, unsigned> salariesByName;
std::transform(
std::begin(employees),
std::end(employees),
std::inserter(salariesByName, std::end(salariesByName)),
[](auto const& employee) {
return std::make_pair(
employee.uniqueName(),
employee.salary()
);
}
);
The std::inserter is similar to the back_inserter, but it needs an iterator it uses to call insert on. In the case of std::map this is a hint to where the element might be inserted. The lambda does the actual transformation of an Employee to a map entry.
Now, this doesn’t look nearly as crisp and clear as the first for loop we had earlier, does it? No worries, it gets better.
Tranform with a condition
Having the salaries of all employees listed is very interesting, but maybe your managers don’t want you to know what their paycheck looks like. So, we get the additional requirement to keep managers’ salaries out of that map. In case of our original loop, the change is simple:
std::map<std::string, unsigned> salariesByName;
for (auto const& employee : employees) {
if (!employee.isManager()) {
salariesByName[employee.uniqueName()] = employee.salary();
}
}
The loop gets slightly more involved but is still readable. We might not be convinced that using an algorithm here is necessary to make it more readable. But let’s see how it looks like if we do. Usually, algorithms with a condition, or, in standardese, a predicate, have the suffix _if in their name. There’s std::copy_if to copy only things that satisfy a condition, and std::find_if and std::remove_if work on elements that match a predicate instead of a value. So, the algorithm we’re looking for is transform_if. But that doesn’t exist in the standard library. Bummer. Luckily, it’s not hard to implement when we have a peek at the implementations of std::transform and std::copy_if. So now we start our own algorithms library. The whole code now looks like this:
template <typename InIter, typename OutIter,
typename UnaryOp, typename Pred>
OutIter transform_if(InIter first, InIter last,
OutIter result, UnaryOp unaryOp, Pred pred) {
for(; first != last; ++first) {
if(pred(*first)) {
*result = unaryOp(*first);
++result;
}
}
return result;
}
//...
std::map<std::string, unsigned> salariesByName;
transform_if(
std::begin(employees),
std::end(employees),
std::inserter(salariesByName, std::end(salariesByName)),
[](auto const& employee) {
return std::make_pair(
employee.uniqueName(),
employee.salary()
);
},
[](auto const& employee) {
return !employee.isManager();
}
);
Now we have two lambdas – the transformation and the predicate. The latter traditionally is the last argument to an algorithm. If we were serious about writing transform_if, this wouldn’t be all. There are four versions of std::transform we’d have to implement the predicated versions for.
This doesn’t look obvious at all – I’d take the three line for loop (five if you count closing braces) over this monstrosity any time.
What about performance?
This is the question that will always pop up, and the first answer I’ll always give is here: First, write readable code. Second, check if performance matters in this case. Third, measure, measure, measure.
As for readable code, I’ve implied my preference above. In these simple cases, the for loops seem more readable. Secondly, we’re constructing new containers and filling them. This should happen once per input, and definitely not in a tight loop. In any case, the insertions into the map will allocate memory. Memory allocation will be much more of a performance hit than the difference between loops that we write versus loops that a library implementer has written.
But of course, I also did some initial measurements using QuickBench:
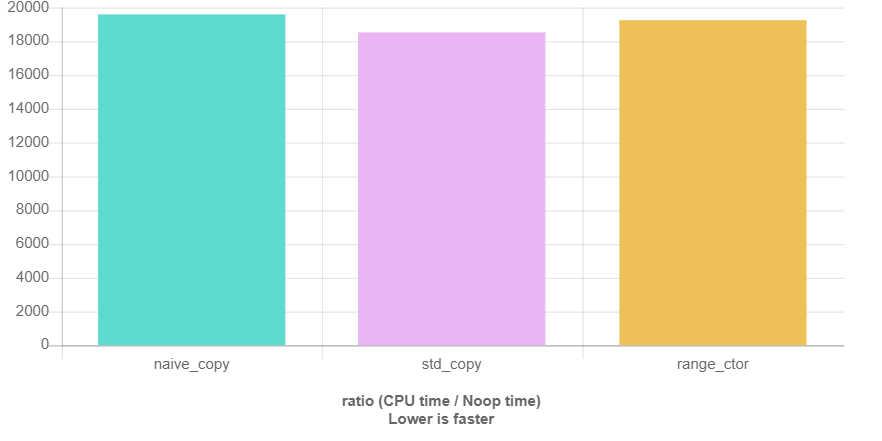
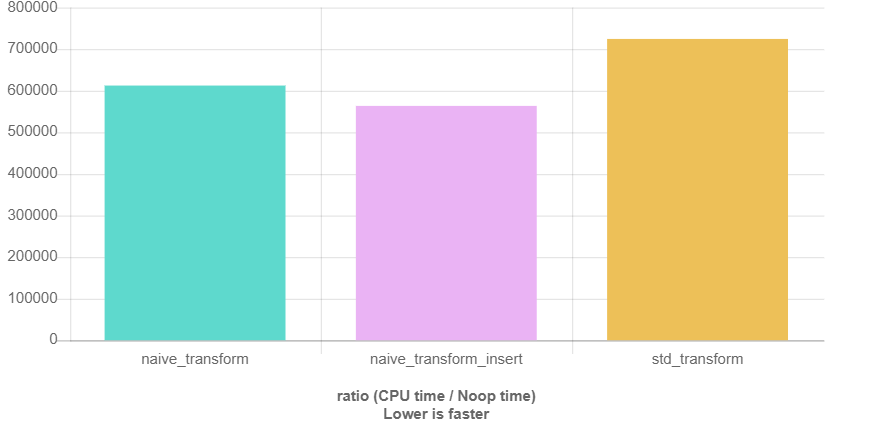

Here, the measurements labeled “naive_” are the for loops I’ve shown above, and there’s one measurement for each of the above code snippets. The containers contained 100.000 Employee structures with names “uniqueName_1” through “uniqueName_100000”, in randomized order. I didn’t analyze the reasons why the algorithms perform worse for the map insertions. My best guess is that it’s due to the insert_iterator having the wrong hin in most cases. Running the same benchmarks with a sorted input vector looks very different. What we can see is that the difference between algorithms and for loop performances is small compared to the overall run time of the loop.
What about ranges?
With C++20 we get Ranges. With ranges, copying the elements of the custom container would look like this:
OtherContainer<Employee> source;
auto employees = source | std::ranges::to_vector;
I leave it to you whether this is clearer than the iterator range constructor – it looks more elegant to me. I didn’t measure performances though.
The transform_if example could look like this:
auto salariesByName = employees
| std::view::filter([](auto const& employee) {
return !employee.isManager();
})
| std::view::transform([](auto const& employee) {
return std::make_pair(
employee.uniqueName(),
employee.salary()
);
})
| to<std::map>;
We see the same two lambdas we had before, but it is more structured since each lambda is passed to a function with a descriptive name. Personally, I still like the for loop, as it’s more compact. However, with any more requirements, the loop will become less obvious very quickly.
Conclusion
The rule to prefer algorithms still applies: Whenever you see a raw for loop, check if it can be replaced by an algorithm (or ranges, if available). However, the rule is more like a guideline: Don’t follow it blindly but make a conscious choice. Prefer whatever is simpler and more readable, and be aware of other alternatives like iterator range constructors.
Permalink
I agree with you that KISS goes first than NO RAW LOOPS (I use capitals as some are intending it as if it was mandatory).
I remember Sean saying repeatedly that “no raw loops” was a goal, not a rule. See the lower case.
I remember Sean saying to consider raw loops with a small number of line 1 to 3 when the code is more readable, which I believe all of as agree most of the time.
The examples you use seems simpler using raw loops than functions. The distance is clearly minimized when we raise the abstraction level with ranges. In any case, wen I need to do such a thing I tend to finish having an application function that do that, that is, that give the meaning.
insertNonManagersFrom(salariesByName, employees);
@Rainer If the raw loop is small enough there shouldn’t be too much difficulties in transforming it to a parallel algorithm by using the appropriated std algorithm.
Concerning the verbosity of the lambda expressions, clearly we need something less verbose. There have been some proposal. Hopping they will e resurrected for C++23.
Permalink
I have implemented the “transform_if” as a reduce.
Using the accumulate and an empty container as an initial value.
Now seeing your code, it doesn’t seems right.
Permalink
I like that you do not fall for the dogma “always use std algorithm”. If the loop is more readable than the std algorithm, it’s a strong point for the loop.
However, that fact that C++’s algorithms are hard to read makes me actually sad. Because for me, that’s a strong point against using the language in the first place.
In Java, the first example would have been something like
employees.stream().collect(toMap(employee::uniqueName, employee::salary)).
Or python: {employee.uniqueName: employee.salary for employee in employees}. These statements allow me to concisely state my intent.
So I am also looking forward to C++20 ranges, they seem like a big improvement in this regard.
Permalink
I’ve never considered a range-based for loop as “raw”. I can see how we wouldn’t consider it an algorithm, but the advice to never use “raw loops” always seemed to apply to for loops (with indexes or iterators).
I’m with you though, the ranged-based for loop is much better for readability.
Permalink
There is are an important additional benefit when you use algorithms of the STL. Today the for loop should run sequential, tomorrow parallel or vectorised. When you write a loop you have to encode the execution policy into the loop. This is not maintainable. But with the parallel STL of C++17, you can say:
std::transform(std::execution::seq, …
std::transform(std::execution::par, …
std::transform(std::execution::par_unseq, …