

In his third guest post, Matt Bentley shows us the impact of cache-locality on performance, using plf::list, his implementation of a cache-local linked list as example.
Folks love to make monolithic statements in IT, or in fact in life in general.
It’s one of those things which makes us feel special – here’s that “hidden truth” that everybody else has forgotten, you’re Smart, they’re Dumb and Wrong. So here’s one of those statements: O(1) time complexity operations are better than O(n) time complexity operations. Are they? How long does the O(1) operation take compared to the series of O(n) operations? This seemed an obvious truth in computing for a long time.
As many have pointed out, back “in the day” (‘the day’ means the entire 1980’s in this context) processor speeds were on par with memory speeds, and this meant that for the most part, O(1) was usually better than O(n) for sizeable amounts of data. But as time drew on, what we once considered ‘sizeable’ became smaller and smaller. Operations which might’ve legitimately been O(n) at some point, were now effectively O(1) when it came to what the hardware was doing. Then when we entered the new millennia with long CPU pipelines and a large performance gap between memory and CPUs, data locality became a damn sight more important than time complexity. And so life goes.
The point is not, of course, that data locality is forever going to be more important than time complexity, but it certainly is right now and for most hardware and the majority of situations. In ten years time, if we stumbled across a new form of computing or a way of making memory as fast as CPUs, then those facts might reverse again. There is no reason to suspect that some other aspect of computing might not make a greater performance difference in even two years time. Massively parallel computing is on the rise. Who knows. As Mike Acton has said: “the hardware is the platform, not the software”, ergo, when hardware changes, the approach to software has to change, if stability and performance are relevant – and they always are.
A case in point: linked lists used to be the bees knees. They had O(1) almost-everything! Erase an element in the middle of the container? O(1). Insert an element at the beginning of the container? Still O(1). Find? Okay, so that’s O(n), but the rest are mostly O(1). In the 80’s, dynamic arrays (ie. C++ std::vector style containers) were not only tricky to use (all that pointer invalidation!), but if you inserted or erased anywhere but at back of the container you got a walloping great O(n) operation! No thanks!!! But nowadays the situation is very different and the O(n) aspect less relevant. Even in the context of erasing from random locations, you still tend to get better performance from a std::vector than a std::list, due to the fact that std::vectors have better data locality.
All this is thanks to changes in computing hardware. So a couple of years ago I decided to focus on how linked lists could be made more appropriate for today’s computers. They are, after all, useful for a number of scenarios including multithreaded work (due to low side effects for operations) and large/non-trivially-copyable elements (due to a lack of reallocation during operations). The first thing to do was get rid of individual allocations of list nodes. Data locality matters, as does the number of allocation operations, so this new linked list allocates chunks of multiples nodes. The second thing I did was use ‘free lists’ to keep track of which elements were erased so I could re-use their memory locations later, saving further allocations and increasing data locality.
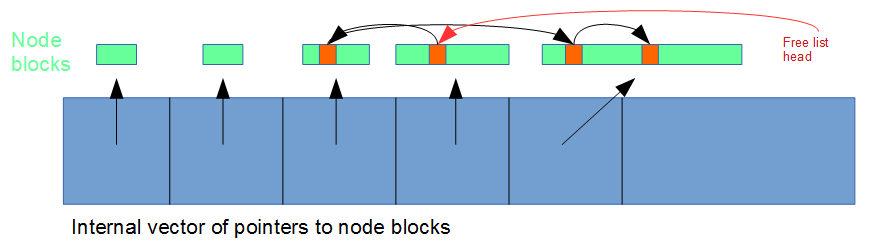
If you’re not familiar with the concept of a free list, in this context there’s a head pointer to the node of the first erased element, and the ‘next’ field of that node points to the next erased node, and so on. I experimented with per-memory-chunk free lists and global free lists, and found per-chunk free lists to be better for a couple of reasons. The first was that they don’t incur a performance penalty when removing a chunk. When using a global free list you have to iterate through the whole free list in order to remove nodes belonging to that chunk. But with a per-chunk free list you erase the free list along with the chunk. The second advantage was that in the context of inserting to the middle of the linked list, they made finding erased nodes close to the insertion point faster. Why is that important? Data locality (again).
If we’re iterating over a regular linked list we’re typically jumping all over the place in memory, unless we’re using a custom allocator, because each node is allocated individually. This slows down performance, due to the fact that CPUs read data from memory in large chunks, and store those in the (much faster) CPU cache. So, if the next element in the linked list doesn’t happen to be in that first memory chunk, it won’t be in the cache either, which means another (slow) read from memory. This means that traditional linked list iteration is typically quite slow. Following pointers doesn’t help much either as it throws off the CPU’s ability to predict the next read location, but there’s nothing much that can be done about that while still having it be a linked list.
So ideally, in a chunk-based linked list, we want to have the elements which are next to each other in the order of iteration also close to each other in memory placement, to minimise the number of memory reads. In the case of insertion, with a per-memory-chunk free list we can quickly (in O(1) time!) check to see if there are any erased elements in the same chunk as the insertion location, and if so, reuse them. Provided we don’t make the chunks too large the likelihood of those two elements (the newly-inserted element and the element it is being inserted next to) being read into cache at the same time increases dramatically.
The final thing I wanted to do was to increase the performance of list sorting. Linked lists have rightly been maligned as being poor choices for sort operations, due to their (again) poor locality and better algorithms being available for containers whose elements are able to be accessed via indexes. Again, back ‘in the day’, linked list sorting was nice because you never had to move any elements around, only write to pointers. Nowadays that’s less relevant, again with the exception of large or non-trivial elements.
So anyway, I hacked the process. I created an array of pointers to the current elements, then sorted it based on the values of the elements those pointers pointed to. Because arrays allow indexing, I was able to use faster sort algorithms which rely on indexing. Then, using those pointers, I processed each node pointed to in turn, making it’s ‘next’ field point to the next element pointed to in the pointer array. Ditto for the ‘previous’ fields, which were pointed to the previous element pointed to in the pointer array. Was this better?
Well. That’s enough sizzle, here’s some steak. On an Intel haswell processor, versus a regular linked list in C++ (std::list), my new abomination (plf::list) had the following stats, on average across multiple type-sizes:
- 333% faster insertion
- 81% faster erasure
- 16% faster iteration
- 72% faster sort
- 492% faster reversal
- 103% faster remove/remove_if
- 62% faster unique
- 826% faster clear (1122550% for trivially-destructible types)
- 1238% faster destruction (6187% for trivially-destructible types)
- 25% faster performance overall in ordered use-case benchmarking (insertion, erasure and iteration only)
(sources: https://plflib.org/benchmarks_haswell_gcc.htm, https://plflib.org/list.htm)
… well heck, I guess that worked huh.
This was further validated once I released it to the public, as I received reports from users whose overall program performance increased by 16% or more when switching from std::list to plf::list. Now you still shouldn’t use linked lists in situations which they’re not appropriate for, and there’s plenty of areas where that’s the case – but if you do have to use one, you’re going to be better off using one that’s designed for today’s computer platforms, not for platforms 40 years ago.
One thing remains to be explained, and that’s the phenomenal increase in speed for destruction and clear’ing, particularly for trivially-destructible types. You might be able to guess this one: in a normal linked list, destruction involves iterating through the list via the previous and next pointers, destructing each element and deallocating the node. For starters, that’s a lot of deallocations. But secondly, you’re forced to iterate over the list regardless of whether you need to destruct the elements. For a chunk-based linked list, you don’t have to iterate in this scenario – you just deallocate the chunks.
But even when you do have to destruct the elements it’s still faster. This is because when you’re destructing/clear’ing a container, the order in which you destruct elements doesn’t matter. Which means in the context of plf::list we can iterate over the element chunks linearly in memory, rather than following the actual linked list’s sequence. Which in turn increases data locality and prefetching performance, thereby reducing iteration time. This process of linearly iterating over elements in memory is also used by the reversal, sort and remove/remove_if operations.
So what can we learn from all this? Obviously, data locality matters a lot at the moment, but more importantly, things change. While it is possible that my linked list will always remain faster than a traditional linked list due to the reduced number of allocations necessary, its also possible that within the next decade or two it’s performance advantages will reduce significantly as CPU’s change and, hopefully, memory speeds increase. But we don’t know.
As always, hardware is the key. All hail hardware.
Permalink
std::dequeis what I use instead of linked lists, mostly, if I need a C++ std library style linked list (external links, not internal links). The usual implementation uses chunks (well, anyway, the MSVC++ version does). But unfortunately it is very much limited by the unaccountable lack of specifying a chunk size. And, sadly, MSVC++ chooses a very small fixed chunk size which you can’t change – small enough that any ordinary struct fills the chunk with only one or two entries. If only the chunk size was a template parameter!Permalink
Main issue with deque is the invalidation of indexes/pointers on non-back insertion/erasure.
If you don’t need stable links, deque is of course fine, with the proviso’s you’ve mentioned. MSVC’s implementation is, as you say, batcrap-crazy. libstdc++’s chunk size is 512bytes or sizeof(element) if element is larger, libc++’s is 4096 or 16x sizeof(element).
Colony does a better job at maintaining valid pointers, and you can specify chunk sizes, only if you’re not worried about insertion order though.
Permalink
I just tell people that if they predict performance based on time complexity alone, they better be talking about some project they wrote on an Arduino, since that’s perhaps the only widely popular platform where “textbook” complexity theory translates directly into benchmark results. As in: there are no caches, it’s a single threaded, scalar, minimally pipelined architecture.
So it’s not that pure time complexity is useless when predicting performance: it’s not, but it’s uses are niche. And telling people that they analyzed complexity of some algorithm as if they intended to run it on an Arduino perhaps helps drive the point home. Yet Arduino is not niche enough to drop below the radar, since even the minuscule Uno still sells and is still a product most of the makers know about.
And of course a modern desktop or mobile platform is not just an Arduino with more memory and faster clock. It’s an interesting (to me) thought experiment to mentally scale it up to GHz clocks and GB memories – it’d be an absurdly expensive platform that couldn’t even be fabricated on a planar PCB: it’d take 3D chip stacking and cooling with I’m not even sure what. Probably you could just run it for a few seconds until it melted, long enough to get benchmark results out 🙂
Permalink
Cool.
One thought: if it is likely that nodes end up in memory in natural order (i.e. a node’s next pointer points to the next location in memory).
Imagine you set a flag in the nodes for which this is true, and when you iterate a list you test this flag to know how to find the next node. If flag is true, just use current++, if flag is false then read next pointer.
This way, when you iterate through naturally ordered nodes, branch prediction might kick in and just linearly read memory, rather than chasing pointers that actually point to the next memory location.
I don’t know enough about branch prediction and CPU architecture to even know if this question makes sense, pardon me if it doesn’t!
Permalink
In most of the situations for which linked lists have a performance advantage (ordered situations with high amounts of non-back insertion/erasure) the likelihood of linear storage becomes smaller, and the penalty for branching higher (as branch prediction will fail more often).
I imagine the extra storage necessary + the branch instructions + extra code would mitigate positive benefit in the linear scenario but I could be wrong. Would require testing to prove one way, or the other.
Permalink
Hey, thanks for the feedback. Thinking about this in the meantime, I was pretty sure the answer would be: it depends.
It was still worth trying to be the one to unlock a few more % of performance 🙂
It’s just your “Following pointers doesn’t help much either as it throws off the CPU’s ability to predict the next read location, but there’s nothing much that can be done about that while still having it be a linked list.” sentence that got me thinking is there really nothing we can do!
Cheers!
Permalink
For me your question makes total sense!
I haven’t looked on his implementation yet (but I will soon).
I think that a better approach to the flag idea could be: each chunk of data has a small Header description for this chunk of data.
It could contain information like the chunk length, protection, stored item size and etc. Then, you have a pointer to the next chunk (contiguous or not) and something similar to scatter gather lists you could have large contiguous sets of data with smaller described portions. Would You, maybe, save time and space comparing to the flag idea?
What do you think?
Permalink
Yay, I didn’t go as far as really imagine an actual implementation. The flag was just to illustrate the idea.
I finally understood is this: what you and I are talking about is a clever trick that will bring benefit for certain usage patterns and drawbacks otherwise. I would not like to be the one that has to tell the users of our linked-list not to erase and insert stuff at random, because otherwise our optimizations to back-fire! That’s the very reason they want to use the linked-list!
On the other hand, what Mr. Bentley here implements is a linked-list that works well on certain hardware. No specific use case for the list, just a clear invitation: if you use modern hardware, use this list. Otherwise use another one. Easy to understand, no unintended back-firing.
Permalink
As I understand it there are three predominant use-cases for lists:
1 is in multithreaded/parallel-processing scenarios where the low side-effects of list insertion/erasure (particularly front element erasure) make it ideal for not creating issues between threads.
2 is where the performance benefits of a linked list benefit the scenario – as far as I can tell from benchmarks the only scenario where this is the case is ordered iteration scenarios with high ratios of non-back insertion/erasure to iteration.
3 is where people need ordered iteration and require pointers which stay stable regardless of insertion/erasure.
Of the above 3, the last can be more efficiently performed using something like a “indexed vector” combined with a free-list , as described in my benchmarks:
plflib.org/benchmarks_haswell_gcc.htm#comparitiveperformance
If either of the 2nd or 3rd categories don’t require ordered iteration a colony will be a better fit.
I’m not sure if theres any dominant scenario where usage would favour the flag technique described, performance-wise. But if there is it might be in the 1st category above.
Permalink
The current implementation uses a custom vector of pointers to node blocks, while each node block already has metadata of the form you’ve described.
One thing I’ve considered is implementing an ‘unordered_iterator’ which would linearly iterate over the memory blocks rather than following the pointers. However, for this kind of use-case, you’d probably want plf::colony rather than a linked list. I don’t know if a use-case exists which requires both strictly-ordered iteration And would also benefit from slightly faster unordered iteration in certain areas.
Permalink
Nice work. The chunks sounds like paged pools.