

Contents
It’s time to write about project file organization again (See part 1 and part 2). Recently I came across two cases of confusion concerning dependencies and generated code that, in my opinion, could have been easily avoided.
Repositories of project dependencies
We usually don’t get away writing a program without a bunch of dependencies. Often enough, our projects get big enough that we want to structure them into different subprojects that depend on each other.
Separating the code of those subprojects into different directories is only natural, and, if possible, we’d also like to separate them into separate libraries. In some cases, the latter may not be possible or desirable. But the separation into directories still remains a good practice.
In a recent project, the developers had decided to divide the product into two separate components that were both depending on a set of base functionality that had to be compiled into the two components. The top directory structure, therefore, looked something like this:
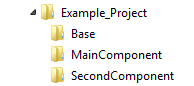
For reasons I won’t go into now, the two components had to be compiled together with the base functionality. Therefore, the version control was configured to place a copy of Base inside each component’s directory. (Ouch)
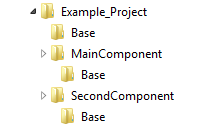
Well, that’s not it: Since the whole project consisted of the MainComponent and the SecondComponent, there was a master project file that referenced both subproject files. It was situated in the MainComponent directory. Logic dictates that the version control system thus has to place a copy of SecondComponent into the MainComponent directory:
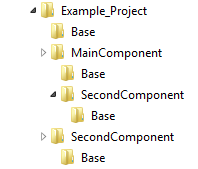
Please resist
While this organization may look sensible if you know the project, it can be a major point of confusion for new team members. Usually, project files and build system files are perfectly OK with having relative paths like ../Base/something for include paths, paths to additional libraries and the like.
In fact, it can be beneficial to have a dedicated directory for build and project files parallel to the source directories. That way, if you want to support multiple build systems, you don’t overload your source directories with the multitude of non-source files.
Generated code
Another project, another confusion: A part of another project relied on a lot of generated code. The generated code would be compiled and linked together with the handwritten source code, and some of the handwritten code would not even compile standalone because it included generated headers.
The poor isolation of generated and handwritten components aside, this was not the main problem. The location of the generated files was: they were put into the same directories as the handwritten sources.
This leads to serious problems: A new team member can never tell which files are generated and which ones are not. The same goes for version control systems. If the number and names of the generated files are not fixed, it will be hard to maintain a list of these files to be ignored by version control.
The only way would be to generate that list as well, which will make the code generation step depend on the version control ignore file format. Cleaning up the generated files would also only be feasible using version control, but that might clean other files as well.
Instead, having a dedicated folder for the generated files would get rid of those issues. It might pull generated and handwritten files apart that are tightly coupled, but that is by far the smaller problem. In addition, more often than not, generated code has a separate purpose from the rest of a code base, so setting it apart into its own directory or even library may actually be the right thing to do in the first place.
Conclusion
Even in a small code base, organize your files in a way that enables new contributors to find their way. The principle of least surprise does not only apply to the code itself, but also to its organization.
Permalink
If you are interested in package management, you might find http://teapot.nz interesting. In particular, all packages exist in a flat hierarchy, and generated files are built into a cache prefix so never part of source code management.
Permalink
Thanks for writing on this topic. I place computer generated files in the same directory as handwritten code. I try to mitigate any confusion by using a “zz” prefix for generated files. This has a grouping effect on them, but doesn’t go as far as using a separate directory. There’s also a comment at the beginning of generated files that makes it clear (if you don’t know what the prefix means):
// Code generated by the C++ Middleware Writer version 1.14.
Permalink
I agree, a dedicated folder for generated code is good. We use a useful convention of putting “.g.” in the names of generated files, eg: “HelloWorld.g.h”. Then, source control exclusions can be set up to ignore files containing “.g.”.